Open Science in unserer Praxis: So offen wie möglich, so geschlossen wie nötig



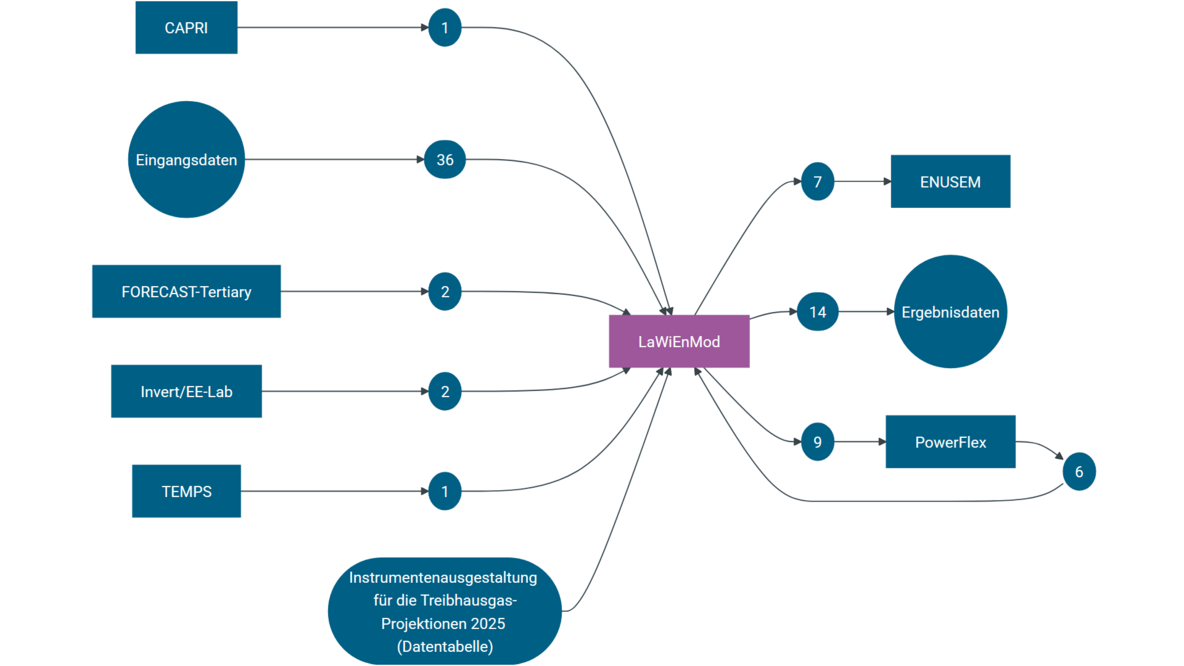

Datenflussdokumentation eines Modells der Treibhausgasprojektionen
© Öko-Institut für Umweltbundesamt
Achtung jetzt wird es technisch – und spannend. Im Bereich Energie & Klimaschutz nutzen wir oft Computermodelle und produzieren mit ihnen relevante Ergebnisse. Im Sinne der Wissenschaft wäre es ideal, wenn unsere Modelle mit ihren Eingangsdaten und die Ergebnisse als offenes Wissen geteilt werden könnten. Das ist nicht immer möglich. Deswegen haben wir eine Dokumentationsweise entwickelt, die sich Open Science annähert und unseren Nebenbedingungen gerecht wird: so offen wie möglich und nur so geschlossen wie nötig.
Offenes Wissen & Open Science
„Wissen ist offen, wenn jedeR darauf frei zugreifen, es nutzen, verändern und teilen kann – eingeschränkt höchstens durch Maßnahmen, die Ursprung und Offenheit des Wissens bewahren,“ wird der Begriff bei OpenDefinition definiert.
Auf Wikipedia wird es so beschrieben: „Open Science ist ein Oberbegriff für verschiedene Ansätze einer offenen Wissenschaftspraxis, bei der möglichst alle Schritte des Forschungsprozesses […], und zwar unter Bedingungen, die die Wiederverwendung, Weiterverbreitung und Vervielfältigung von Forschung und den ihr zugrundeliegenden Daten und Methoden ermöglicht.“ Hier ist auch die Wichtigkeit von Open Science gut dargelegt: „Mit der Öffnung der Wissenschaft werden verschiedene Zielstellungen verfolgt, darunter bessere Sichtbarkeit und Transparenz, Nachvollziehbarkeit und Reproduzierbarkeit der Forschung, mehr Diversität und Inklusion in der Wissenschaft, bessere Qualitätssicherung sowie eine verbesserte Nachnutzbarkeit.“
Open Science in unserer Praxis
In unserem Bereich bearbeiten wir viele Projekte für Auftraggebende mit Hilfe von Modellen. Diese nutzen Eingangsdaten, sogenannte Inputs. Mittels der in den Modellen abgebildeten Mathematik errechnen die Modelle mit Hilfe der Inputs Ergebnisse, so genannte Outputs. Daher wäre es im Sinne von Open Science, wenn unsere Modelle, Inputs und Outputs als offenes Wissen geteilt werden könnten. Das ist aber nicht immer möglich, da sowohl Daten als auch Modelle oft mit Restriktionen versehen sind.
Wir haben daher überlegt, wie wir so offen wie möglich werden können. Für ein wichtiges vom Umweltbundesamt gefördertes Projekt haben wir daher eine Dokumentationsweise entwickelt, die sich Open Science annähert und den Nebenbedingungen der jeweils involvierten Daten und Modelle gerecht wird.
So offen wie möglich: Beispiel
Die offiziellen deutschen Treibhausgasprojektionen müssen gemäß §5a des Bundes-Klimaschutzgesetzes jährlich der Bundesregierung und gemäß Artikel 18 der EU-Governance-Verordnung in allen ungeraden Jahren der EU-Kommission vorgelegt werden. Diese Projektionen basieren auf einer komplexen Modellierung, die sehr umfangreichen Berichtspflichten genügen muss. Diese sind in der Durchführungsverordnung (EU) 2020/1208 Anhang XXV festgehalten.
Wegen der Komplexität ist nur eine ausgewählte Anzahl von Modellen in der Lage, die Projektionen zu erstellen. Derzeit sind 18 Modelle aus den sechs Institutionen Öko-Institut, Fraunhofer ISI, IREES, M-Five, prognos und Thünen-Institut an dem Prozess beteiligt. Keines dieser Modelle ist momentan vollständig quelloffen. Viele der zu nutzenden Inputs sind ebenfalls nicht unter offenen Lizenzen freigegeben. Dennoch wollten wir offene wissenschaftliche Standards anwenden, um hohe Transparenz und mögliche Nachnutzungsmöglichkeiten für Dritte zu schaffen.
Wie sieht es aus?
Die Onlinedokumentation ist interaktiv und deckt drei zentrale Bereiche ab:
- Der Modellierungsprozess wird durch interaktive Grafiken dokumentiert, deren Elemente klickbar sind. So lernen Nutzende, welche Daten von wo nach wo fließen, z.B. welche Daten als Input in ein Modell fließen. Auch welche Daten von einem zu einem anderen Modell fließen ist dokumentiert.
- Die Modellfaktenblätter informieren standardisiert über zentrale Charakteristika aller eingesetzten Modelle.
- Die Datenfaktenblätter informieren ausführlich über in der Modellierung eingesetzten Datensätze. Ist ein dokumentierter Datensatz für die Weiternutzung verfügbar, ist er im Datenfaktenblatt verlinkt.
Das Technische dahinter: Wie haben wir das umgesetzt?
Eine unserer größten Herausforderungen war die große Bandbreite an technischem Fachwissen der circa 30 Dokumentierenden. Unser Ziel war es, den auf Ontologien und RDF-Wissensgraphen basierenden Dokumentationsprozess für alle unkompliziert zugänglich zu machen. Begegnen konnten wir unserer Herausforderung mit Hilfe von Trainings am Anfang des Dokumentationsprozesses und folgenden technischen Spezifika:
- Eine selbst gehostete GitLab-Instanz für Versionskontrolle, Transparenz und automatisierte Datenverarbeitung
- JSON Schemas für die Metadaten-Dokumentation und Validierung, basierend auf DCAT-AP.de 2.0
- GitLabs integrierter VSCode-Browser-Editor, zusammen mit dem JSON-Schema, der es den Dokumentierenden ermöglicht, Metadaten direkt in JSON-Dateien einzugeben und zu validieren (Gültigkeitsprüfung, Hilfetexte, Dropdowns …)
- Automatisierte Konvertierung in RDF-Wissensgraph via JSON-LD Annotation
- Automatisierte Erstellung der Dokumentation aus RDF-Wissensgraph
Dr. Hannah Förster koordiniert Treibhausgasprojektionen im Bereich Energie & Klimaschutz am Standort Berlin. Ihr liegt Open Science am Herzen. Christian Winger ist Datenspezialist. Er arbeitet im Bereich Energie & Klimaschutz am Standort Freiburg.
Weitere Informationen
THG-Projektionen 2025 für Deutschland. Daten- und Modelldokumentation
Code und Vorlagen für eigene Inspiration
Treibhausgas-Projektionen 2025 für Deutschland (Projektionsbericht 2025)
Meldung „Projektionsbericht 2025: Deutschland verfehlt langfristige Klimaziele“







